На Programmableweb опубликован рассказ Дэниэля Джекобсона, директора разработки NPR. Он описывает крайне логичный и рациональный принцип, который внутри NPR получил название COPE: Create Once, Publish Everywhere. Дэниэл говорит о принципиальной разнице между инструментами публикации в веб (web publishing tools) и системами управления содержимым (CMS). Если первые предназначены для представления контента исключительно в веб-форматах (HTML, картинки + иногда CSS, нередко внедрённый в разметку), то вторые хранят контент в максимально чистом виде, без или с минимумом специфичной для веба разметки, позволяя таким образом быстро и безболезненно создавать для содержимого новые представления — будь то версия для мобильных устройств, RSS или полноценный буклет в PDF для печати.
Небольшая презентация Дэниэля наглядно иллюстрирует принцип COPE:
Я довольно часто наталкиваюсь на разговоры о семантической разметке в вебе. На мой взгляд, работоспособность любой технологии зависит от того, насколько удобно и понятно её поддержка реализована для конечного пользователя, в данном случае контнет-менеджера. Очень многие современные CMS хотя и не столь явно ориентированы на выдачу HTML (большинство из них может отдавать данные также XML-форматах: RSS, Atom и т.д.), однако подход к хранению информации остаётся достаточно примитивным.
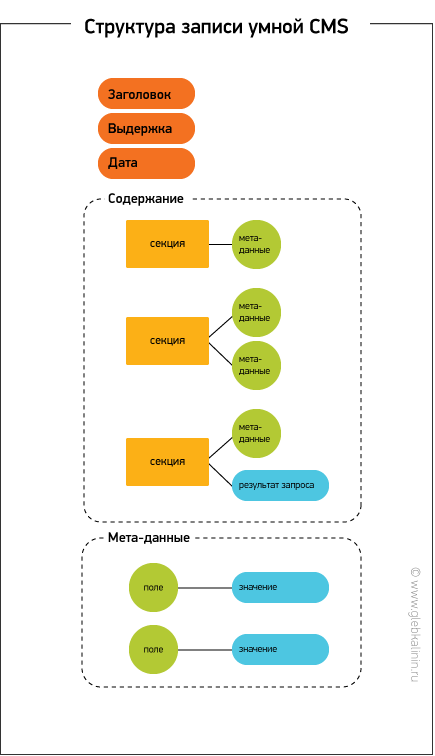
Типичные CMS представляют такой подход к хранению данных: «атомарными» являются поля заголовок и содержимое, в некоторых случаях краткая аннотация, к ним привязан набор дополнительных мета-данных, файлы, теги, категории и т.д. Однако основной массив информации, собственно содержание записи, хранится в виде единой строки, с прописанной структурой, если таковая имеется, и разметкой, семантической в меру знаний контент-менеджера.
Ситуация эта мне кажется не очень правильной. На мой взгляд, CMS должна предоставлять возможность в простом и наглядном режиме создавать новые типы записей, данные в которых хранятся максимально дискретно и представляют собой связки «поле—значение», при этом значением могут быть данные из других записей того же или другого типа. То, что в терминологии стандартных CMS является единым полем «содержимое», также может представлять из себя набор связанных полей.
Схематически это могло бы выглядеть примерно так:
Кстати, интересный концепт под названием upflow (демо, github) предлагает использовать markdown в качестве разметки, при этом отображает её в визуальном режиме. Такой подход называется WYSIWYM — What You See Is What You Mean. Несмотря на то, что при нём, очевидно, всё содержимое всё равно хранится одной записью, такой метод всё же способствует созданию структурированных документов, а не каши из тегов, как в случае с визивигом, хотя и требует от редактора куда большей сообразительности и понимания процесса и не заменит качественного интерфейса и продуманной структуры хранения данных.
При такой системе мне не приходилось бы как сейчас вручную писать разметку для того, чтобы делать боковые сноски. Я бы настроил CMS таким образом, чтобы к каждому абзацу или секции можно было привязывать примечание, или картинку, или файл, и не создавал в определенной степени привязанные к оформлению теги с классами, а просто заполнял соответствующее поле. В упрощённом и схематичном виде интерфейс мог бы выглядеть примерно так (клик — просмотр увеличенной версии):
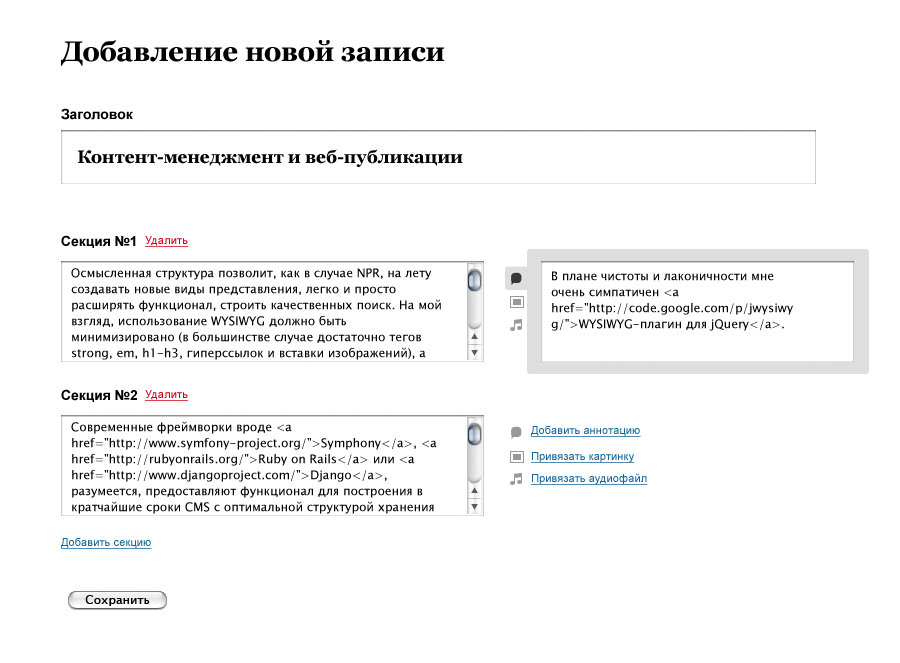
Естественно, это довольно грубый прототип, не учитывающий многих нюансов.
Осмысленная структура позволит, как в случае NPR, на лету создавать новые виды представления, легко и просто расширять функционал, строить качественных поиск. На мой взгляд, использование WYSIWYG должно быть минимизировано (в большинстве случае достаточно тегов strong, em, h1-h3, гиперссылок и вставки изображений), а результат работы визуального редактора должен тщательно чиститься. (В плане чистоты и лаконичности мне очень симпатичен WYSIWYG-плагин для jQuery.) Чем дискретней, атомарней данные, тем легче их организовывать, сортировать, повторно использовать, анализировать. Вместо склада текстов можно формировать базы данных, извлекая из них новые смыслы и значения.
Современные фреймворки вроде Symphony, Ruby on Rails или Django, разумеется, предоставляют функционал для построения в кратчайшие сроки CMS с оптимальной структурой хранения данных, однако я пока не встречал удобных инструментов, не требующих навыков программирования для решения типовых задач по созданию специфичных структур данных. Мне кажется, что при нынешнем развитии технологий это вполне посильная задача для очень большого процента случаев.
Кстати, на завтрашнем Хакдее я буду читать доклад о контенте, и непременно затрону и этот вопрос. Мне было бы интересно обсудить его с профессиональными программистами.